
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- Market
- Computer Vision
- OKR
- 컴퓨터비전
- 파인튜닝
- 데이터모델링
- nlp
- dl
- 모델링
- productmarketfit
- DACON
- 그로스해킹
- tableau
- omtm
- fit
- 데이터시각화
- 언어지능딥러닝
- 머신러닝
- pmf
- product
- 태블로
- 데이콘
- ERD
- 시각화
- 인공지능
- 딥러닝
- 자연어처리
- 데이터분석
- Today
- Total
블로그
[모델링] 개인 소득 수준 예측 AI 모델 개발 본문
데이콘에서 간단해보이는 대회 발견
"수업 내용 좀 복기해서 분석 연습 좀 해보자" 하고 시작했다.
연습할 때는 코드가 빨리빨리 잘 쳐지는데 실전에선 항상 어떻게 해야 할 지 잘 모르겠다 ..
연습을 많이 해봐야겠지?
목표
개인의 특성과 관련된 다양한 데이터를 활용하여 개인 소득 수준을 예측할 수 있는 AI 모델을 개발
데이터
- ID : 학습 데이터 고유 ID
- Age : 나이
- Gender : 성별
- Education_Status : 교육 상태
- Employment_Status : 고용 상태
- Working_Week(Yearly) : 연간 근무 주
- Industry_Status : 산업 상태
- Occupation_Status : 직업 상태
- Race : 인종
- Hispanic_Organic : 히스패닉 유무(히스패닉: 스페인어권 국가 출신 이주자 및 그 후손)
- Martial_Status : 결혼 상태
- Household_Status : 가구 상태
- Household_Summary : 가구 요약
- Citizenship : 시민권
- Birth_Country : 출생 국가
- Birth_Country(Father) : 아버지 출생 국가
- Birth_Country(Mother) : 어머니 출생 국가
- Tax_Status : 세금 상태
- Gains : 이득
- Losses : 손실
- Dividens : 배당금
- Income_Status : 소득 상태
- Income : 1시간 단위의 소득
ID를 제외하고 21개의 피처로 Income을 예측해야 한다!
데이터 분석
Age

# scatter_r : 산점도와 상관계수를 출력하는 함수(사용자 정의)
scatter_r(train.groupby('Age', as_index=False)[target].mean(), 'Age', target)
# PearsonRResult(statistic=-0.06691490402869421, pvalue=0.5285570191496242)
- 피어슨 상관계수는 약 -0.07, p-value는 약 0.53으로 둘은 별로 연관성이 없다고 나왔으나, 나이별 소득의 평균값으로 그래프를 그려보니 위와 같은 형태가 나왔다.
- 아무래도 직급이 높아진 40대가 가장 소득이 많고, 그 전후로는 적어지는 것 같다.
- 아주 관계가 없다고는 할 수 없을 것으로 보인다.
Working_Week (Yearly)

scatter_r(train.groupby('Working_Week (Yearly)', as_index=False)[target].mean(), 'Working_Week (Yearly)', target)
# PearsonRResult(statistic=0.6678328814586645, pvalue=4.690088416919997e-08)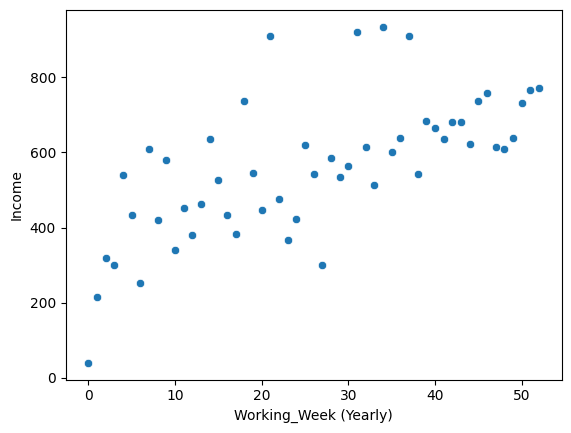

- 연간 근무 주별 소득의 평균을 산점도로 그려보니 선형 관계가 있음을 확인할 수 있었다!
- 상관계수와 p-value를 확인해봤을 때도 유의미한 관계가 있다는 것을 알 수 있다.
Education Status
import numpy as np
# 조건 목록
conditions = [
(train[feature].isin(['Kindergarten', 'Children', 'Elementary (1-4)', 'Elementary (5-6)', 'Middle (7-8)'])),
(train[feature].isin(['High Senior', 'High Freshman', 'High Sophomore', 'High Junior'])),
(train[feature].isin(['High graduate', 'College', 'Bachelors degree', 'Associates degree (Vocational)', 'Associates degree (Academic)'])),
(train[feature].isin(['Professional degree', 'Doctorate degree', 'Masters degree']))
]
# 해당 조건에 대응하는 값 목록
values = ['bh', 'bc', 'ubd', 'abd']
# np.select를 사용하여 조건에 따라 'edu_cat' 열 설정
temp['edu_cat'] = np.select(conditions, values, default='Unknown') # 모든 조건이 거짓일 경우 'Unknown'
- 범주가 너무 많은 피처는 더 큰 범주로 묶어보았다.
- 수업 때 피처가 많으면 Random Forest 같은 트리 기반 모델을 사용해서 Feature Importance를 확인해보았는데, 여기서 사용해보면 좋을 것 같다는 생각이 들었다 !
Feature Importance


- Random Forest 모델로 모든 변수를 사용해 예측을 수행한 후, Feature Importance를 확인해보았다.
- train 피처를 중요도 순으로 정렬한 후, 개수를 조절하면서 가장 높은 성능을 보이는 지점을 확인했다.
모델링
scikit-learn 패키지 기반의 AutoML 라이브러리인 pycaret를 사용해서 모델 선정 및 학습을 수행했다.
우선 내가 선정한 피처로 모델 학습을 수행했지만, rmse가 약 569.3정도로 성능이 좋지 않았다. (1위가 532정도였음!)
한 피처를 제외한 모든 피처를 사용했을 때 성능이 가장 좋았다.
처음에 로그 변환과 정규화 없이 학습시켰을 때는 성능이 형편없었는데 , 로그 변환이 성능 개선에 큰 도움을 줬다 !!
진작에 생각했어야 됐는데 ,,ㅠ 담번엔 기억해서 바로 적용하즈아
import pandas as pd
import numpy as np
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
dumm_cols=['Gender', 'Education_Status', 'Employment_Status', 'Industry_Status', 'Occupation_Status', 'Race', 'Hispanic_Origin', 'Martial_Status', 'Household_Summary', 'Citizenship', 'Birth_Country', 'Birth_Country (Father)', 'Birth_Country (Mother)', 'Tax_Status', 'Income_Status']
# Household_Status와 가변수화시 test에 존재하지 않는 피처들 제거
train = pd.get_dummies(data=train, columns=dumm_cols, drop_first=True, dtype=int)
train.drop(['ID', 'Household_Status', 'Birth_Country_Holand-Netherlands', 'Birth_Country (Father)_Panama'], axis=1, inplace=True)
test = pd.get_dummies(data=test, columns=dumm_cols, drop_first=True, dtype=int)
test.drop(['ID', 'Household_Status'], axis=1, inplace=True)
# 대부분 0이고 매우 큰 값의 이상치가 있는 피처에 log 적용
log_cols = ['Gains', 'Losses', 'Dividends']
for i in log_cols:
train[i] = np.log1p(train[i],)
test[i] = np.log1p(test[i])
x = train.drop('Income', axis=1)
y = train['Income']
# Min Max Scaling
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
x_s = scaler.fit_transform(x)
train = pd.DataFrame(x_s, columns=x.columns)
train['Income'] = y
test_s = scaler.transform(test)
test = pd.DataFrame(test_s, columns=test.columns)
# pycaret
from pycaret.regression import *
exp_clf = setup(data = train, target = 'Income', session_id=2024, use_gpu=True, train_size=0.9)
best_model = compare_models()
lgbm = create_model('lightgbm') # 가장 성능이 좋은 모델
catboost = create_model('catboost') # 두 번째로 성능이 좋은 모델
tuned_lgbm = tune_model(lgbm, n_iter=50, optimize='rmse', search_library='optuna')
tuned_catboost = tune_model(catboost, n_iter=50, optimize='rmse', search_library = 'optuna')
# 두 모델 soft voting
blended = blend_models(estimator_list = [tuned_lgbm, tuned_catboost],
fold = 10,
optimize='rmse',
)
# 최종 모델 선정
final_model = finalize_model(tuned_lgbm)
# 예측
prediction = predict_model(final_model, data = test)
# 0 이하 값으로 예측한 경우, 0으로 대체
prediction.loc[prediction['prediction_label'] < 0, 'prediction_label'] = 0
최종 1,162명 중 76등 !! 이지만 AutoML 라이브러리를 사용하지 않는게 대회 규칙이었는데 그걸 대회가 끝나고 알았다 ㅋㅋㅋㅋㅋ
규칙을 어겼기 때문에 의미있는 등수는 아니지만... 10%안에 들어서 잠깐이나마 기분이 좋았다 ㅋㅋㅋ
진짜 언제나 느끼지만 데이터 분석을 꼼꼼히 하고... 모델을 이것저것 조합해보는게 중요한 것 같다..,,
그리고 규칙보기...^^ 다음번에는 규칙 좀 꼼꼼히 읽고 해야겠다
성능 안나오는 것 같다고 데이터 분석 포기해버리지 말고 끝까지 합시다......,,
'공부' 카테고리의 다른 글
| [Tableau] 스타벅스 메뉴 데이터 / 매장 정보 데이터 분석 및 대시보드 제작 (0) | 2024.05.24 |
|---|---|
| [Tableau] 1일차 Tableau 개요 (태블로 소개, 데이터 전처리, 시각화, 서버 업로드) (0) | 2024.05.23 |
| [모델링] 장애인 콜택시 대기시간 예측 (0) | 2024.04.02 |
| [학습] 공공데이터포털에서 공휴일 데이터 가져오기 (0) | 2024.04.02 |
| [모델링] 사용자 행동 인식 데이터 멀티 라벨 분류 (0) | 2024.03.30 |



