
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- product
- OKR
- dl
- Computer Vision
- 파인튜닝
- productmarketfit
- omtm
- 시각화
- tableau
- 자연어처리
- 태블로
- 딥러닝
- 언어지능딥러닝
- 데이터분석
- 데이터시각화
- ERD
- 컴퓨터비전
- 머신러닝
- 그로스해킹
- 데이콘
- pmf
- DACON
- 데이터모델링
- fit
- nlp
- 인공지능
- Market
- 모델링
- Today
- Total
블로그
[모델링] 장애인 콜택시 대기시간 예측 본문
목표
- 당일 콜택시 운행이 종료되었을 때, 다음 날의 콜택시 대기시간을 예측
데이터
- open_data.csv : 장애인 콜택시 운행 정보
- weather.csv : 날씨 데이터
데이터 기본 탐색
- 주기별 분석을 위해 날짜 변수 추가
df['Date'] = pd.to_datetime(df['Date'])
df['Day'] = df['Date'].dt.day
df['Weekday'] = df['Date'].dt.weekday # 요일 숫자(weekday_name으로 주면 요일 이름 반환)
df['Week'] = df['Date'].dt.isocalendar().week # 주차
df['Month'] = df['Date'].dt.month
df['Year'] = df['Date'].dt.year
- 주기별 분석
1) 일별 (차량 운행 수, 접수건, 탑승건, 탑승률, 대기시간, 운임, 이동거리)
- 탑승률, 운임은 일별 차이가 크지 않음







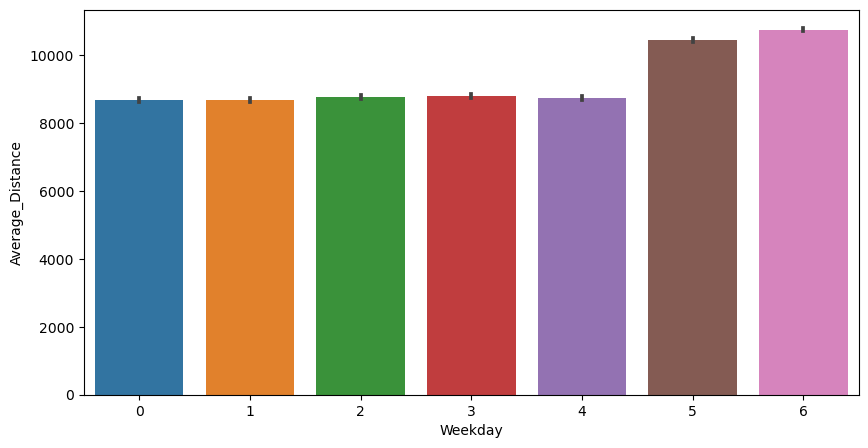
2) 요일별 (차량 운행 수, 접수건, 탑승건, 탑승률, 대기시간, 운임, 이동거리)
- 요일별 차량 운행 수, 접수건, 탑승건, 대기시간, 운임, 이동거리에 유의미한 차이가 보임 (평일 주말 차이 뚜렷)
- 주말에 접수건, 탑승건 모두 적고 탑승률은 평일, 주말 비슷함






3) 월별 (차량 운행 수, 접수건, 탑승건, 탑승률, 대기시간, 운임, 이동거리)
- 탑승률, 운임, 이동거리를 제외하고는 유의미한 차이가 보임
- 계절별로 묶어보면 확실한 차이가 있을까?







4) 연도별 (차량 운행 수, 접수건, 탑승건, 탑승률)
- 2020년도 이후 차랑 운행 수가 증가
- 2020년도 접수건, 탑승건 급감




데이터 구조 만들기
- 날짜 관련 변수 추가 : 요일, 월, 계절, 연도
data['weekday'] = data['Date'].dt.day_name()
data['weekday'] = pd.Categorical(data['weekday'], categories=['Monday','Tuesday','Wednesday','Thursday','Friday','Saturday','Sunday'])
data['month'] = data['Date'].dt.month
data['season'] = np.where(data['month'].isin([3,4,5]), 'Spring',
np.where(data0['month'].isin([6,7,8]), 'Summer',
np.where(data0['month'].isin([9,10,11]), 'Fall', 'Winter')))
data['season'] = pd.Categorical(data['season'], categories=['Spring','Summer','Fall','Winter'])
data['year'] = data['Date'].dt.year
- 공휴일 피처 추가
# 방법1 : workalendar 패키지 설치 후, 대한민국 공휴일 정보 가져오기
# !pip install workalendar
from workalendar.asia import SouthKorea
cal = SouthKorea()
holiday = pd.DataFrame(cal.holidays(YEAR))
# 방법2 : 공공데이터 포털 한국천문연구원_특일 정보 api 사용하기
# !pip install xmltodict
import requests
import pandas as pd
import xmltodict
REST_API_KEY = 'YOUR_DECODE_SERVICE_KEY'
url = 'http://apis.data.go.kr/B090041/openapi/service/SpcdeInfoService/{INPUT_METHOD}'
params = {'serviceKey':REST_API_KEY, 'solYear':YEAR, 'numOfRows':60}
response = requests.get(url, params=params)
holiday = pd.DataFrame(xmltodict.parse(response.text)['response']['body']['items']['item'])
- 7일 이동 평균 시간
- 2022년 데이터를 예측해야 하는데, 학습데이터와 예측할 데이터의 값 차이가 큼
- 연도를 분리해서 학습 및 예측해보려고 했는데 성능은 좋지 않았음
data['mv7_Wait_Time'] = data['Average_Wait_Time'].rolling(7).mean()
# 이동 평균선
plt.figure(figsize = (18,6))
sns.lineplot(x='Date', y='mv7_Wait_Time', data=data)
plt.ylim(0,100)
plt.grid()
plt.show()

탐색적 데이터 분석
- 단변량 분석
- 평균 운임과 평균 거리는 매우 연관이 있을 것이다.
- 평균대기시간과 이의 파생 변수들도 모두 연관이 있을 것으로 보인다.
- 탑승률은 정규분표 형태를 띔
- 이변량 분석
- target과 탑승률, 전날의 대기시간 => 선형관계가 있는 것으로 보이지만, target 자체가 대기시간 데이터로 만들어낸 데이터이기 때문에 관계가 있을 수밖에 없음
- 날씨 요소에는 큰 영향을 받지 않는 것으로 보임
- 습도에서 아주아주 약한 선형관계를 볼 수 있었음
- 휴일(공휴일+주말)간의 target값에 유의미한 차이가 있었다
- 요일간에도 차이가 있었음 -> anova 결과를 봤을 때도 유의미한 차이가 있는 것으로 나옴
- 계절간에도 유의미한 차이가 있음
- covid 컬럼을 생성해서 2020, 2021년에 해당하는 행에 1을 부여했는데, covid간에도 유의미한 차이가 있었음
[강한 관계의 변수]
- 7일 이동평균, 전날 평균대기시간
[중간(약한) 관계의 변수]
- 탑승률, 접수건, 탑승건, 요일
[(거의) 관계가 없는 변수]
- 운행 차량 수, 평균운임, 평균 이동거리
모델링 결과
나 전 날 콜택시 정보가 무슨 상관인가 싶어서 그냥 예측할 날의 요일, 계절, 공휴일(주말) 여부 세 피처만 가지고 모델링에 들어갔다.
Linear Regression이 가장 좋은 성능을 보였다.
( MAE: 4.229672594408698, MAPE: 0.1019432598355691, R2: 0.10603561498610015 )

그래프 모양 진짜 오바죠 ?
날짜 파생변수 외에 만들 수 있는게 있나 싶었는데 불쾌지수나 장애인의 날 등 이벤트 관련해서 새로운 피처를 만들 수 있다는 걸 배웠다.
이것저것 만져보고 피처도 만들어보고 해야되는데 안한다 ^.^ 좀 해라!!!!!!!!!!!!!!!!!!!!!!!!!!
'공부' 카테고리의 다른 글
| [Tableau] 1일차 Tableau 개요 (태블로 소개, 데이터 전처리, 시각화, 서버 업로드) (0) | 2024.05.23 |
|---|---|
| [모델링] 개인 소득 수준 예측 AI 모델 개발 (0) | 2024.04.08 |
| [학습] 공공데이터포털에서 공휴일 데이터 가져오기 (0) | 2024.04.02 |
| [모델링] 사용자 행동 인식 데이터 멀티 라벨 분류 (0) | 2024.03.30 |
| [모델링] 스마트폰 센서 데이터 기반 행동 인식 분류 # 2 단계별 모델링 (0) | 2024.03.29 |



