
반응형
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
Tags
- product
- productmarketfit
- 데이터모델링
- 파인튜닝
- 언어지능딥러닝
- ERD
- fit
- 머신러닝
- 컴퓨터비전
- 그로스해킹
- DACON
- OKR
- 인공지능
- tableau
- 자연어처리
- 태블로
- 딥러닝
- 데이터분석
- dl
- 시각화
- nlp
- Computer Vision
- pmf
- 데이콘
- 데이터시각화
- 모델링
- omtm
- Market
Archives
- Today
- Total
블로그
[논문 리뷰] Application of Machine Learning for Assessment of HS Code Correctness 본문
공부
[논문 리뷰] Application of Machine Learning for Assessment of HS Code Correctness
beenu 2023. 9. 8. 01:20반응형
Abstract
- hs 코드의 정확성을 수동으로 평가하는 것은 오류가 발생하기 쉽고, 시간이 많이 소요됨
- 머신러닝을 사용하여 제품의 텍스트 설명을 통해 학습한 품목분류 코드의 정확성 평가
- 품목의 hs 코드의 정확성을 평가하기 위해, 텍스트의 코사인 유사도와 hs 코드의 의미론적 유사도를 기반으로 한 새로운 결합 유사도 측정 방법을 도입
- 의미론적 유사도 : hs코드 간의 관계나 계층 구조를 기반으로 한 유사도로, 같은 상위 카테고리에 속하는 두 hs 코드는 높은 의미론적 유사도를 가짐
Related works
- 대부분의 관련 연구는 다양한 기계 학습 방법을 사용하여 판매자의 관점에서 자동 상품 분류에 중점을 둠
- 이 논문은 위험 관리 시스템의 일부로 사기 탐지에 중점을 둠
- 자연어 텍스트에 보완적인 지식으로 HS 코드 분류의 구조를 사용
- Application of Machine Learning for Automated HS-6 Code Assignment(Ruder, 2020)
- 결과적으로 DNN 분류기가 TF-IDF로 추출된 특징을 사용하여 61%의 F-1 가중 평균 점수와 62%의 정확도를 보이며 이는 현재 인간의 작업에 의해 평균적으로 달성된 정확도보다 훨씬 높은 수준임
Preliminaries
1. HS code definition and classification taxonomy(HS 코드 정의 및 분류학)

- hs코드는 ‘is-a’ 관계로 표현됨(계층 구조로 이루어짐)
- 이는 방향성 비순환 그래프(DAG)로 볼 수 있음
- 하나의 hs코드가 동시에 여러 헤딩에 속할 수 없음
- DAG (방향성 비순환 그래프)
- 방향성 그래프 : 그래프의 각 엣지에는 방향이 있음, 시작노드와 끝 노드 존재
- 비순환 : 한 노드에서 시작하여 같은 노드로 돌아오는 경로가 없음
- 모든 노드는 다른 노드로 향하는 엣지를 가질 수 있지만, 어떤 노드에서 시작하여 자신으로 돌아오는 경로는 없음
- 특정 개념에서의 종속성을 나타내거나 데이터의 흐름을 표현하는 데 사용됨
- 위상정렬이 가능하다 → 위상정렬은 노드들을 선형 순서로 나열하는 것을 말하며, 이 순서는 그래프 엣지들의 방향을 모두 만족함
2. Similarity measures (유사도 측정)
a. 유사도 정의 : 주어진 엔티티 집합 O에 대해, 유사도 s는 두 객체 간의 유사도를 나타내는 실수로서의 함수이며 이 때 유사도는 양수, 최대성, 대칭성을 만족해야 함
- positiveness(양수성) : 유사도의 값은 일반적으로 0과 1 사이 값을 가짐
- maximality(최대성) : 동일한 항목을 비교할 때, 유사도는 최댓값을 가져야 함
- symmetry(대칭성) : 두 항목 A와 B 사이의 유사도는 B와 A 사이의 유사도와 동일해야 함

b. 텍스트 기반 유사도 측정
- 품목의 설명은 짧은 텍스트로 구성됨
- 텍스트 엔티티는 벡터로 변환되며 이를 통해 일반적인 거리 측정 방법(ex. 유클리디안 거리 등)을 사용하여 유사도 계산
- 주로 bag-of-words, TF-IDF 방법 또는 Word2Vec, Doc2Vec, GloVe와 같은 단어 임베딩을 사용하여 텍스트 엔터티의 피처 벡터를 계산
- Word2Vec는 단어의 표현 벡터를 생성하는 데 사용되며, 신경망을 사용하여 단어를 저차원 벡터 공간에 임베딩
- 벡터 공간에서 가까운 벡터는 문맥에 따라 유사한 의미를 갖고, 서로 멀리 떨어진 벡터는 다른 의미를 갖게 됨
- 단어의 텍스트 유사도는 두 단어 벡터 간의 코사인 유사도로 측정할 수 있음
- 이 연구에서는 품목의 짧은 설명을 문서라고 가정하고 Doc2Vec 모델을 사용하여 문서에 대한 표현 벡터를 생성함 → 코사인 유사도를 사용하여 텍스트 설명 간의 유사도 측정
c. 의미론적 유사도 측정
- hs코드는 분류학적으로 배열됨(계층구조)
- hs코드의 구조적 지식을 기반으로 한 의미 거리 방법을 적용할 수 있도록 함
- 이 연구에서는 분류학의 상대적 깊이를 고려하는 Wu&Palmer 유사도 측정 방법을 적용함
- Wu&Palmer(1995)
- LCS(Least Common Subsumer)의 깊이와 함께 WordNet 분류법의 두 synset의 깊이를 고려하여 관련성을 계산함
- 개념 간의 상대적 깊이를 고려하여 유사도 측정
- 따라서 분류학의 상위 수준에 속하는 동일한 거리의 개념 쌍은 하위 수준에 속하는 개념 쌍보다 덜 유사하다고 간주(거리를 1이라고 했을 때, 세모 하위 그룹의 유사도보다 세모와 네모의 유사도가 더 낮음)
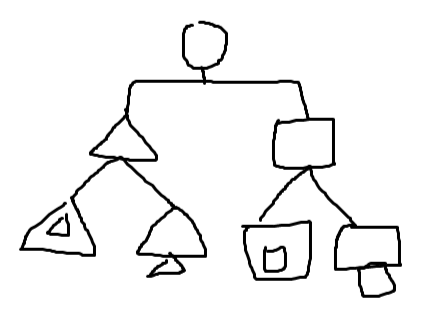
- LCS : 두 개념 c1과 c2의 가장 낮은 공통 조상

LCS(Boat, Car) = Vehicle
- WordNet : 영어의 의미 어휘목록. WordNet은 영어 단어를 'synset'이라는 유의어 집단으로 분류하여 간략하고 일반적인 정의를 제공하고, 이러한 어휘목록 사이의 다양한 의미 관계를 기록
A proposed combined similarity measure
- A new combined similarity measure
- Doc2Vec 모델을 적용해 본 결과, 유사한 문서가 동일하거나 유사한 HS 코드와 항상 연관되어 있는 것은 아님 → 제품 설명의 텍스트가 너무 짧기 때문임
- 가설 : 주어진 HS 코드와 해당 품목 설명 텍스트가 얼마나 잘 일치하는지 파악하기 위해서는 HS 코드의 분류 체계를 고려해야 함
- 두 가지 유사도를 결합하여 새로운 유사도 측정 방법인 결합 유사도 (CombSim)를 정의함
- 텍스트 유사도 (CosSim): 제품 설명 간의 코사인 유사도를 사용하여 텍스트 유사도를 계산함. 이는 Doc2Vec 모델을 사용하여 얻은 문서의 표현 벡터를 기반으로 함.
- 의미론적 유사도 (WPSim): HS 코드 분류학 내에서 두 HS 코드 간의 의미론적 유사도를 계산함. 이는 Wu and Palmer 방법을 기반으로 함.
- 장점 : HS 코드의 구조(분류학)에서 추가적인 지식을 추출하여 제품의 짧은 텍스트 설명만으로는 부족한 지식을 보완한다는 것
- Properties of combined similarity measure
- 양수성, 최대성, 대칭성 만족
HS code correctness assessment method
- An overview of the method
- 평가할 각 HS 코드에 대해 관련 제품 설명(거래)이 제공되어야 하며 이러한 데이터는 외부 시스템 또는 출처에서 제공됨
- 이 방법을 사용하기 위해서는 주어진 제품 텍스트 설명 집합에 대해 학습할 HS 코드 명명법(즉, 분류 분류법)과 Doc2Vec 모델을 사용할 수 있어야 함
- Doc2Vec 모델은 코사인 유사도 값을 계산하고 HS 코드 값을 예측하는 데 사용됨
- 예측된 HS 코드 값은 WPSim 공식과 주어진 HS 코드 분류 체계에 따라 의미적 유사성을 계산하는 데 사용됨
- 코사인 유사도 및 해당 의미적 유사도 값을 기반으로 CombSim 공식에 따라 결합 유사도 측정값 계산이 수행됨
- 마지막으로, 결합된 유사도 값은 HS 코드 정확도 평가 점수 계산에 사용됨
- Calculating textual similarities and prediction of HS code values
- 단어 임베딩은 주어진 단어의 주변 단어(워드벡터)를 예측할 수 있는 방법이며 대표적으로는 Word2Vec이 있음
- SkipGram(SG) : 중심 단어 기준으로 주변 단어 예측
- CBOW : 주변 단어 기준으로 중심 단어 예측
- 단어 수준의 표현에는 효과적이지만 특정 문서의 의미를 표현하는 데는 부족할 수 있으므로 문서 임베딩 알고리즘 Doc2Vec 사용
- 단어 임베딩 기법을 기반으로 하며, 문서에 특정한 주변 단어 벡터를 추출하는 데 사용됨
- 문단 벡터는 주어진 문맥에서 다음 단어를 예측하기 위해 문단의 여러 단어 벡터와 연결됨(Le and Mikolov, 2014).
- Paragraph Vector - Distributed Memory(PV-DM) : Word2Vec CBOW와 유사함. 문맥 단어 벡터와 전체 문서 문서 벡터의 평균을 기반으로 중심 단어를 예측하는 작 업에 대해 신경망을 훈련하여 얻음
- Paragraph Vector - Distributed Bag of Words(PV-DBOW) : Word2Vec SG와 유사함. 전체 문서의 문서 벡터만으로 그 문서 내의 특정 대상 단어를 예측하는 합성 작업에 대해 신경망을 훈련하여 얻음(Le and Mikolov, 2014)
- Word2Vec은 유사한 단어에 대해서 동일한 벡터가 할당되지만 Doc2Vec은 무작위성으로 인해서 동일한 벡터가 반환되지 않음 → 동일한 문서라도 코사인 유사도 1이 나오지 않음, 그렇더라도 여전히 1에 가깝다
- 무작위성의 주요 원인
- 초기 가중치 설정: 신경망 모델을 학습할 때, 초기 가중치는 주로 무작위 값으로 설정됩니다. 이 초기 설정은 모델의 학습 경로와 결과적인 문서 벡터에 영향을 줍니다.
- 미니 배치 학습: 대부분의 딥러닝 모델은 전체 데이터를 한 번에 처리하는 대신 미니 배치(mini-batch)라는 작은 데이터 덩어리를 사용하여 학습합니다. 이 미니 배치의 선택 순서는 학습 결과에 무작위성을 추가합니다.
- 학습률 감소: 학습률(learning rate)은 학습 과정에서 조정될 수 있으며, 이 조정은 무작위성을 도입할 수 있습니다.
- 정규화 및 드롭아웃: 정규화나 드롭아웃 같은 기술은 모델의 과적합을 방지하기 위해 사용되지만, 이러한 기술들도 학습 과정에 무작위성을 추가합니다.
- 무작위성의 주요 원인
- 유사성 계산을 위해 우선 Doc2Vec 모델을 사용하여 주어진 텍스트(품목 설명)에 대한 가장 유사한 문서(hs코드에 대한 설명)를 찾음
- 이 모델은 미리 학습된 데이터를 기반으로 작동하며, 각 문서에 대한 벡터 표현을 생성하며 이 벡터 표현은 문서 간의 코사인 유사도를 계산하는 데 사용됨
- Doc2Vec 모델을 사용하여 반환된 유사한 문서의 수는 실험적으로 결정됨
- 예를 들어, "laptop computer"라는 텍스트에 대해 가장 유사한 8개의 문서를 반환할 수 있고, 각 반환된 문서는 해당 HS 코드와 함께 태그가 지정됨
- 유사한 문서와 그 문서의 HS 코드를 사용하여, 원래 문서의 HS 코드를 예측
- 예를 들어, "laptop computer"에 대한 가장 유사한 문서 중 하나가 "desktop laptop"이고 해당 HS 코드가 847150인 경우, 이 HS 코드는 원래 문서의 HS 코드로 예측될 수 있음
- 단어 임베딩은 주어진 단어의 주변 단어(워드벡터)를 예측할 수 있는 방법이며 대표적으로는 Word2Vec이 있음
- Assessment of HS code correctness on the basis of combined similarity
- 이전 단계의 결과로 예측된 각 HS 코드에 대해 주어진 제품 설명과 관련된 코사인 유사도(CosSim), HS 코드 분류에 따라 주어진 HS 코드와 관련된 의미적 유사도 (WPSim), 결합 유사도(CombSim)를 구함
- HS 코드 분류에 따라, 주어진 HS 코드와 예측된 HS 코드의 불일치하는 분류 수준 각각에 대한 W P Sim 값을 사전에 계산할 수 있음. 왜냐하면 분류는 0에서 4까지의(10단위의 경우 더 깊겠죠?) 고정된 수준의 트리 구조를 가지고 있기 때문에 계층 구조를 미리 파악할 수 있기 때문임.
- hs 코드 평가 점수 생성 방법
- 예측된 HS 코드 목록을 CombSim 값의 내림차순으로 정렬하고 CombSim이 가장 적합한 HS 코드의 WPSim을 반환
- 품목 설명과 각 HS 코드 설명 간의 유사도를 계산하여 가장 유사도가 높은 HS 코드를 찾음. 찾아진 HS 코드와 실제로 품목 설명에 맵핑된 HS 코드 간의 wpsim을 계산함. 이렇게 해서 두 HS 코드가 얼마나 의미론적으로 가까운지를 판단하는 것
- 반환된 WPSim을 점수로 변환함
- 점수를 HS 코드 평가 점수(HSScore)로 반환함. HS 코드 정확성 평가를 위한 머신 러닝 적용
- 점수를 매기는 과정에 들어가기 전에 HS 코드 체계에 따라 유효하지 않은 HS 코드가 이미 감지되고 제거되었다는 것을 전제로 함
- 예측된 HS 코드 목록을 CombSim 값의 내림차순으로 정렬하고 CombSim이 가장 적합한 HS 코드의 WPSim을 반환
Method evaluation and experimental results
- Data sources and data preprocessing
- HTS(미국 무역 대표부(USTR)에서 사용하는 국제 상품 분류 체계)가 null이 아닌 레코드만 필터링하고 필수 필드를 선택 - 항목 설명, HTS
- 항목 설명에서 알파벳이 아닌 문자를 모두 제거하고 항목 설명이 비어 있는 모든 레코드를 제거
- 이 절차는 예를 들어 "laptop123"과 "laptop321"이라는 다른 클래스가 정리 프로세스 후 유사한 결과인 "laptop"을 제공하므로 데이터에 중복이 발생할 수 있음
- HS 코드가 숫자가 아니거나 길이가 6자 미만이거나 HS 코드 챕터가 바운드를 벗어난 모든 레코드를 제거
- 모든 레코드를 제거하면 텍스트는 동일하지만 HS 코드가 달라져 해당 쌍이 하나만 남게 됨
- HS 코드 정확성 평가를 위한 머신 러닝 적용
- 데이터 전처리 결과로 받은 HS 코드와 품목 설명이 포함된 약 120만 개의 행을 데이터 세트를 머신러닝 작업에 사용함
- Training Doc2Vec model
- Data preparation for training
- Gensim 라이브러리와 Python 프로그래밍 언어를 사용하여 방법 구현
- Doc2Vec 모델을 훈련시키기 위해 몇 가지 데이터 준비 단계 수행 후 텍스트를 태그가 지정된 문서로 변환
- 텍스트를 단어 세트로 변환하고, 세트 W에서 다음 단어를 모두 제거:
- {”hs”, ”hscode”, ”hts”, ”htscode”, ”tel”, ”code”, ”pcs”, ”kg”}. 그리고 일반적인 단어(불용어)와 길이가 2 이하인 모든 단어도 제거
- 데이터 세트에서 문서의 인덱스 번호를 사용하여 문서에 고유한 태그를 지정
- Gensim 라이브러리에 따라 문서에 고유하지 않은 태그를 추가. 이 경우 제품 설명과 함께 제공되는 HS 코드가 두 번째 태그로 간주됨 → 고유한 번호는 문서의 인덱스 번호고, HS 코드를 두 번째 태그로 추가하여 모델을 사용해 유사한 제품 설명을 찾을 때 HS 코드 정보를 활용할 수 있게 됨
- 데이터 준비의 결과는 다음 형식의 태그가 지정된 문서 모음:
- (words=["adapter", "laptop", "battery", "mouse", "docks"], tags=["1035312", "847180"]). 위의 예에서 볼 수 있듯이 문서의 고유한 태그는 1035312이고 고유하지 않은 태그는 HS 코드 847180임.
- 태그가 지정된 문서의 컬렉션을 90/10의 비율로 분할하며, 문서의 90%는 훈련 세트로, 10%는 테스트 세트로 사용
- Model initialization
- 초기 학습률(α)은 우리가 사용하는 Doc2Vec PV-DBOW 구현을 위해 0.025로 선택
- 학습이 진행됨에 따라 학습률을 떨어뜨리지 않음 → 따라서 최소 α는 동일함
- 모든 단어를 어휘에 포함시켜서 총 빈도가 어떤 값보다 낮은 단어를 무시하지 않고 모두 사용함
- 훈련 알고리즘은 PV-DBOW, 말뭉치에 대한 반복(에포크) 횟수는 10회
- Doc2Vec은 비지도 학습 알고리즘이므로 자동으로 정확성을 평가하거나 검증하는 방법이 없음 → 사람이 직접 결과를 검토하고 평가하는 것은 가능함
- Data preparation for training
- Using Doc2Vec model
- Calculating text similarities of descriptions of goods
- Doc2Vec 모델을 사용하면 원본 텍스트와 가장 유사한 문서를 찾을 수 있음
- 예를 들어 원본 텍스트 : "laptop computer", 원본과 유사한 텍스트를 찾는 경우
- 먼저 원본 텍스트를 전처리하고 사전 학습된 Doc2Vec 모델을 사용하여 벡터로 변환 → 어휘 내의 텍스트와 원본 텍스트 벡터 간의 코사인 벡터 유사도를 측정하여 가장 가까운 텍스트를 찾음 ⇒ 주어진 원본 텍스트와 가장 유사한 문서 사이의 코사인 유사도를 얻게 됨. 예를 들어, 표 2(첫 번째와 세 번째 열)에는 원본 텍스트 "laptop computer"와 가장 유사한 상위 8개의 문서가 제공되고 이 결과를 통해 제공된 유사도의 의미를 확인하기 위해 수동 검사를 할 수 있음
- Doc2Vec 모델을 사용하면 원본 텍스트와 가장 유사한 문서를 찾을 수 있음
- HS code prediction
- 우리는 HS 코드 예측을 위해 이전에 설명한 텍스트 유사도 접근법을 적용할 수 있음
- 태그가 붙은 문서의 집합을 가지고 있고, 그 중 하나의 태그는 HS 코드
- 우리는 원본 텍스트 문서, 예를 들면 "laptop computer”와 가장 유사한 문서를 찾으려고 시도하면서 태그도 함께 고려함. "laptop computer" 텍스트와 가장 유사한 상위 8개의 문서 결과와 함께 예측된 HS 코드(즉, 태그)도 표에 나와있음
- 표에서 볼 수 있듯이 높은 텍스트 유사도는 항상 예측된 HS 코드의 동일한 값 또는 유사한 값과 관련되어 있지 않음
- Calculating text similarities of descriptions of goods
- HS code recommendation based on text similarity
- Recommending several HS codes
- 가장 유사한 텍스트 검색의 결과를 사용하여 HS 코드를 추천할 수 있음
- 반환하는 유사한 텍스트의 수에 따라 다른 수의 HS 코드를 추천할 수 있음(여러 개 추천)
- 추천 평가 방법 중 하나
- Recommending the unique HS code
- 단 하나의 HS 코드만을 선택하는 알고리즘
- 알고리즘에 대한 가장 명확한 옵션은 가장 자주 사용되는 값을 반환하는 mode 함수를 사용하는 것 → 다중 모드를 가지고 있다면 알고리즘은 그 중 하나만 반환할 것 ⇒ 문서의 코사인 유사도를 가중치로 사용하는 가중 모드 함수를 사용하여 다중 모드 케이스 수 최소화 및 텍스트 간의 거리 고려
- 이 최적 값은 의미론적 유사성 및 결합 유사성을 찾는 데 고려되며 HS 코드 평가 점수를 계산하는 데도 고려됨. 이러한 계산은 Doc2Vec 모델에 의해 반환된 상위 8개의 유사한 문서를 기반으로 함
- 아무튼 상위 8개를 기반으로 계산하는 것이 최적의 방법이다
- Recommending several HS codes
- Computing semantic and combined similarity
- 결합 유사성은 텍스트 설명의 코사인 유사성만을 사용하여 해당 HS 코드의 올바름을 판단하는 것의 부족함을 보완함 → HS 코드 구조, 즉 HS 코드 분류에서의 위치를 고려하기 때문임
- Computing and evaluating HS code assessment score
- HS 코드 평가 점수 평가
- train-test 데이터를 분할한 후 Doc2Vec 모델을 학습 데이터 기반으로 학습시킴
- 테스트 세트에서는 각 텍스트 설명과 할당된 HS 코드 쌍에 대해 HSScore를 할당함
- 테스트 데이터의 hs 코드가 정확하다는 가정 하에 테스트 진행
- 실험 결과에 따르면 약 80%의 경우 점수가 4 또는 3으로 매우 좋은 결과가 나옴
Conclusions and discussion
- 제품 텍스트 설명에 보완재로서 HS 코드 분류를 사용하면 짧은 텍스트에서 얻은 미흡한 지식을 보완하여 HS 코드의 정확성 평가 점수를 더 정확하게 만듦
- 실제 데이터 세트의 제품 설명 품질이 상당히 떨어졌다는 점을 주목해야 함
- 더 나은 품질의 데이터를 사용하면 성능이 더 늘 것
- 본 논문에서 제시된 실험은 결합 유사도 방식이 약 80%의 경우에 정확한 HS 코드 정확성 평가 점수를 할당함을 보여주었으며, 해당 방법이 잘 작동한다는 것을 보여줌
- 개선 사항
- Wu&Palmer 방식 외에 다른 의미론적 유사성 측정 옵션이 있음
- 적절한 분류기뿐만 아니라 Doc2Vec 외의 다른 특징 추출 방법도 조사해야 함
728x90
반응형
'공부' 카테고리의 다른 글
| [학습] 분류 모델 불균형 데이터 평가지표 (0) | 2023.10.03 |
|---|---|
| [학습] PyTorch 토크나이저 저장 (0) | 2023.10.03 |
| [학습] 불균형한 데이터 학습 시 클래스 비율 지정 (0) | 2023.09.21 |
| [학습] Pandas apply 메소드 (5) | 2023.09.11 |
| [논문 리뷰] Neural Machine Translation for Harmonized System Codes prediction (0) | 2023.09.08 |
'공부' Related Articles
more
